
Table of contents
The AI boom is exposing how poor most companies are at managing risk: Gartner says over 40% of agentic AI projects will be abandoned by 2027, largely because leaders never set clear objectives or boundaries for failure.
This is just one example of a deeper paradox facing large organizations. We demand speed, innovation, and agility—but we leave teams without the clarity they need to deliver. We encourage them to “take smart risks,” “fail fast,” and “learn from mistakes,” yet we rarely define what a smart risk actually looks like, what level of failure is acceptable, or how to distinguish bold experimentation from costly error.
The result? Teams either hesitate—sticking to safe bets and incremental gains—or take ill-considered risks that waste resources and erode trust. Failure gets judged through politics and hindsight, not clear pre-agreed criteria.
And in today’s environment, risk avoidance isn’t a strategy. The pace of change—from technology to regulation to customer behavior—demands that companies take smarter risks and learn faster than ever before. What’s missing isn’t the appetite for risk. It’s the playbook for taking the right risks, at the right time, for the right reasons.
As you read through this playbook, remember that you don’t need every team applying the same level of rigor to every initiative. To get started, focus your discipline where stakes are highest:
- When launching a major initiative or strategic bet
- When approving a significant investment
- After a notable failure or near miss
- When entering a new market, tech, or business model
Begin by Defining the Types of Failure
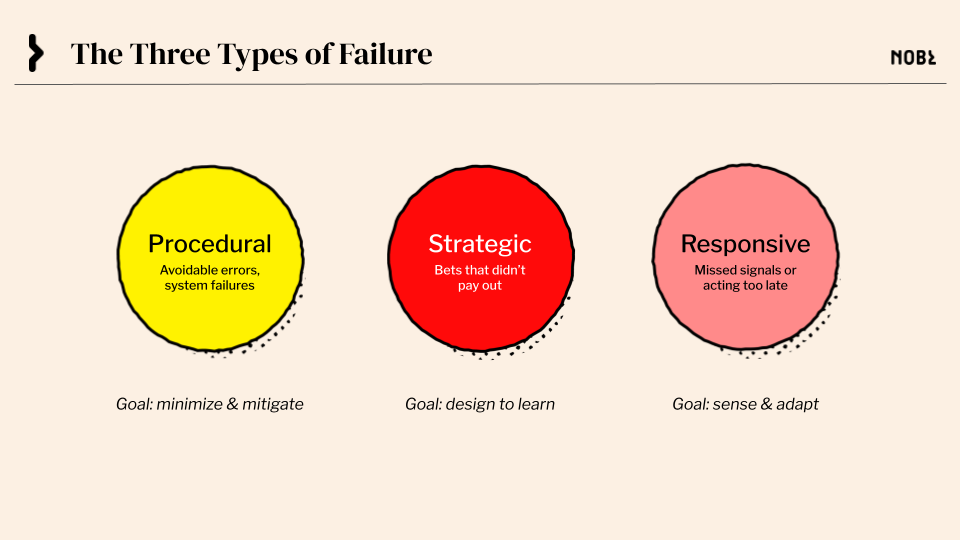
At its core, failure is any deviation from intended outcomes that causes harm, waste, or lost opportunity relative to what you set out to achieve.
But not all failures are created equal. Leaders must help their teams understand the crucial differences—and set expectations for how to handle each type.
1. Procedural failures
These are mistakes in routine or well-understood work—errors caused by skipping critical steps, ignoring proven practices, or allowing dysfunction to take hold. Leaders should make it clear: procedural failures must be minimized, mitigated, and above all, not repeated.
That said, before blaming individuals, examine the system. Incompetence may be the easy story to tell but, in reality, most procedural failures stem from systemic weaknesses: unrealistic timelines, too much work-in-progress, poor documentation, inadequate training, or misaligned incentives. If your organization experiences frequent procedural failures, it’s a signal that your operating system—not just your people—needs attention.
2. Strategic failures
These are bets the organization makes that don’t pay off as intended. The key is distinguishing between calculated bets and careless bets.
A calculated bet is thoughtfully designed, proportionate to the risk, and offers the opportunity to learn and adjust—even if it fails. A careless bet is reckless, hasty, or based on little more than hope.
Leaders should insist that big strategic bets be reasoned and explicit about trade-offs. As our understanding of the environment improves, so should the scale and sophistication of our bets. And if a decision-maker can’t clearly explain the rationale behind a big bet, they shouldn’t be making it.
3. Responsive failures
These occur when the organization fails to see or act on external shifts in time—whether those are new regulations, economic changes, competitive moves, or unexpected customer behaviors.
Surprises are inevitable, especially in uncertain markets or novel projects. The surprise isn’t the failure. The failure is in not detecting it early enough and in missing the window to act. Leaders should expect surprises—and ensure their teams are equipped to scan for change, interpret signals, and mobilize quickly.
Eliminate Fuzzy Goals
Failure can’t be judged if success hasn’t been defined. When objectives are vague—“make it better,” “innovate,” “delight customers”—teams are left guessing at what matters. Leaders must set goals in a way that makes outcomes observable, measurable, and testable. That’s what allows teams to evaluate whether a failure actually occurred.
Here’s a simplified framework leaders can use to shape clearer objectives:
- State the outcome, not just the activity. Define what will be different or better because of the work.
Example: Instead of “launch new feature”, say “increase customer retention by X% within Y months of launch.” - Define measures of success. Attach a metric or observable change to the outcome. This gives the team and the organization a common standard for evaluating results.
Example: revenue growth, error reduction, cycle time improvement, customer adoption rates - Set time boundaries. Specify when success should be achieved. Open-ended objectives are hard to evaluate—and harder to manage.
Example: “achieve target within 6 months of launch” rather than “over time.” - Define acceptable losses. Clarify up front what’s worth risking—budget, time, reputation, opportunity cost—so teams can take action with confidence.
Examples: “We’re prepared to spend three months exploring this new channel. If we don’t see early traction by then, we’ll stop or pivot.” “We’re comfortable testing this positioning with a limited audience, but we’re not willing to risk negative press at a national scale without further validation.”
When leaders follow this discipline, failure becomes a meaningful signal, not a subjective judgment. Teams know where the lines are—and can take smart risks within them.
Demand Calculated Bets
A risk does not become smart simply because it’s bold or popular. It’s smart because it reflects clear thinking and deliberate choice. Leaders must set the expectation that every strategy—the bets the organization makes—has a solid, well-reasoned foundation.
At a minimum, calculated bets require:
1. Clarity on the opportunity
Teams must be able to clearly explain what opportunity they’re pursuing and why it matters. Vague ambition isn’t strategy. The opportunity should connect directly to organizational objectives or uncover new potential worth exploring.
2. Explicit trade-offs
Every strategic choice involves saying no to something else. Teams should be able to articulate what they’re deprioritizing or delaying in order to pursue the bet. This keeps the organization focused and prevents unintentional spread of effort.
3. Alignment of risk and reward
Risk should match potential value. A risk that could meaningfully advance the organization’s position—or provide critical learning—may warrant significant investment. A risk with little upside shouldn’t. Leaders should also be able to look across the organization’s bets and ensure there’s an appropriate mix of risks.
4. Documented rationale
Strategy isn’t just about the decision; it’s about the reasoning behind it. Teams should capture and share the rationale for key bets so that others can learn from what succeeds—and what doesn’t. If teams can’t clearly explain why a bet is worth making, it probably isn’t.
Thoughtful strategy gives teams the license to take risks and the guardrails to take the right ones. Leaders should host venues for proposing and evaluating bets, and hold the discussion to a high level of rigor.
Foster Thoughtful Execution
Even the smartest strategy will fail without disciplined execution. Leaders must set the expectation that teams not only act thoughtfully, but also build the muscles to spot issues early, respond fast, and learn as they go. Execution isn’t about rigidity—it’s about creating the conditions for smart action and fast adaptation.
Prepare to Execute Well
Thoughtful execution starts with getting the basics right:
- Use checklists or process guides for complicated, cross-functional, or high-stakes work. This helps teams avoid basic errors and stay focused on what matters.
- Ensure teams have the resources and clarity they need. If people are under-trained, under-staffed, or unclear on goals, execution will suffer before it even begins.
- Run pre-mortems before major efforts. Take 30 minutes to ask: If this fails, what’s the most likely reason? Adjust your plan accordingly.
Scan for External Shocks
Some events are truly unexpected. But more often, organizations fail because they were oblivious, overly optimistic, or too slow to respond. The earlier you spot trouble, the cheaper and easier it is to address.
- Identify 2–3 key signals to monitor for each major initiative—leading indicators that trouble may be ahead.
- Review those signals regularly. Even a short weekly check-in can help teams catch small problems before they become big ones.
- Make it safe for anyone to raise a flag. The fastest path to resilience is open communication, not hierarchy.
Learn From Failure
The only truly unacceptable failure is the failure to learn. Leaders should make it clear that every misstep is a chance to build organizational strength—if the learning is captured and applied.
- Hold short, blameless retrospectives. Focus on what happened and what should change, not who to blame. Do this at the end of projects, or at least quarterly.
- Build lessons into future practices. Document what was tried and what failed. Where possible, translate those lessons into checklists, playbooks, or decision guides.
- Share learning broadly. One team’s insight can prevent another’s failure—if it’s shared.
Thoughtful execution doesn’t slow teams down. It helps them move faster, with less waste, and greater confidence.
Finally, Test the Value of What You Learned

We’ve all seen it—and done it ourselves. A project falls short, and someone says, “Well, at least we learned something.” It’s a way to soften the blow, to frame failure as progress. But too often, that “learning” is thin comfort: vague reflections, untested assumptions, or feel-good statements that don’t actually change what we do next.
If we want failure to drive real improvement—not just rationalization—we need to get sharper about evaluating what counts as valuable learning. Here’s how leaders can tell the difference between real, useful learning and organizational self-soothing:
Failure is valuable learning if it:
- Is substantiated with data, not just declared. Valuable learning is backed by data, observation, or validation—not just what people say they learned. Without proof, it’s too easy to rationalize failure or create feel-good narratives.
- Is tied to the original assumptions. Good learning helps you confirm or revise the assumptions you made at the start (for example, “We assumed customers would pay for this feature. They won’t—unless X.”). Bad learning is generic or obvious (“Customers liked some parts of our product.”).
- Produces a clear insight that changes future action. The learning leads to a tangible change in how you prioritize, design, build, or decide. If you can’t name what you’ll do differently as a result, it’s not valuable learning.
- Can be shared and applied beyond the immediate team. The learning travels. If it helps another team avoid the same failure or make a smarter decision, it’s valuable. If it stays trapped in a single project debrief, it’s noise.
- Delivers insights worth the cost of failure. If the cost of the failure far exceeds the value of the insight gained, it wasn’t good learning. Valuable learning produces insights proportionate to the investment or loss.













